Machine Learning Notes I - Introduction & Math Review
SVD, MLE, Entropy
All modern machine learning algorithms are just nearest neighbors. It’s only that the neural networks are telling you the space in which to compute the distance.
Linear Algebra
Woodbury Identity
其中
如果
Matrix Derivatives
向量 / 标量
所以假设说
标量 / 矩阵
同样的,对于
酱紫
Jacobian: 向量 / 向量
假设函数是
所以其实我们可以看成是
Hessian: 二阶导
对于函数
所以其实就是
Derivative Rules
我们先来算
将
SVD
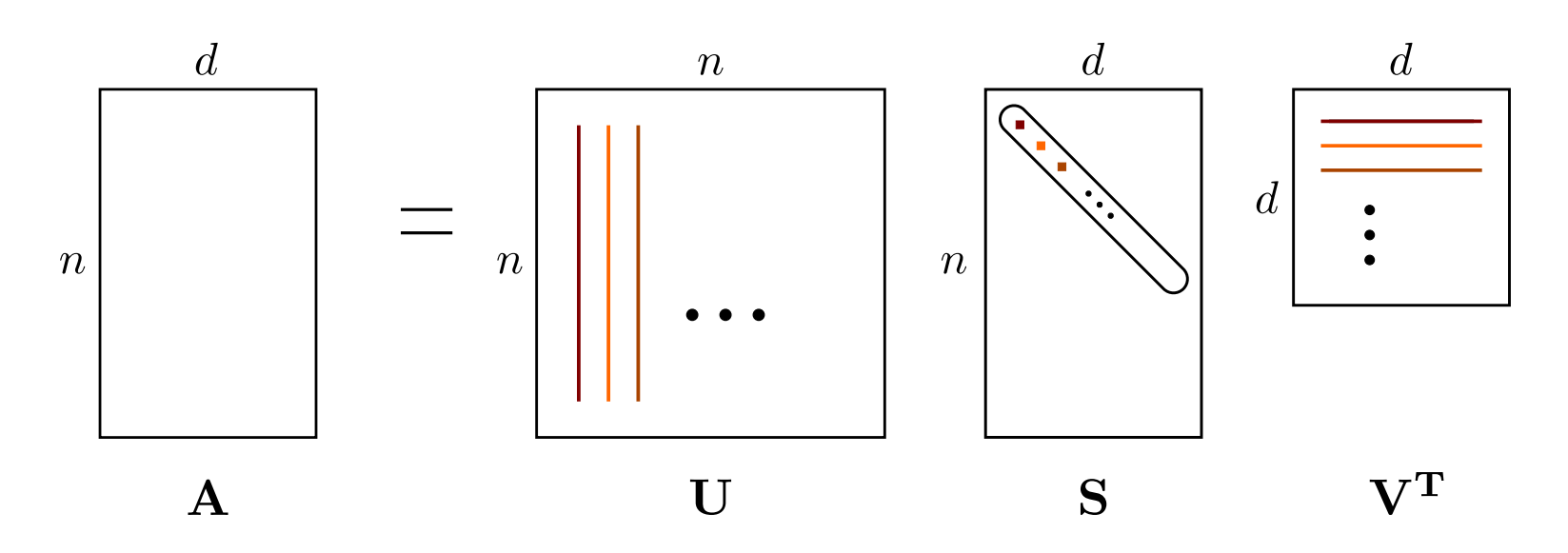
Compute largest
Approximation:
For all rank
Calculus of Variations
变分法中,我们考虑的是对于一个函数的函数
假设
那么
Maximum Likelihood Estimation
Maximum likelihood estimation:
Properties:
- Consistency: more data, more accurate (but maybe biased).
- Statistically efficient: least variance.
- The value of
Entropy
要搞一个 “degree of surprise” 函数
根据 3 我们有
如果我们令
所以
所以
通常我们取
于是我们定义
当然因为 entropy 是从物理来的,他也有一定物理意义。就是我们考虑有
我们考虑定义
其中用到了 Stirling’s approximation
那啥时候